
Running an AI agent with a local or European model can sound like the obvious answer to every concern: data stays closer, dependency on large US cloud providers is reduced, and the project feels easier to explain to employees, clients and partners.
In practice, the useful question is not “local or cloud?”. It is: what data will the agent handle, what quality of answer is required, who validates the output, and what level of operational control is the company ready to maintain?
At Last Word, we usually start with the workflow before choosing the model: what enters the system, what the expected output is, who validates it, and which risks the business accepts. An agent can then coordinate tasks, sources and human review, choosing the right model for each context. A local or European LLM can be part of that architecture. It is not always the best option, and it never replaces proper workflow design.
This article gives founders, operations teams and project owners a practical way to think about local AI agents, Mistral-style European options, cloud services and hybrid architectures without falling for “sovereignty as magic”.
Before choosing the model
Local, European, cloud or hybrid?
Start with the article: qualify the business risk, identify the likely route, then decide whether a workshop or a Last Word service is useful.
Local only matters when it changes the architecture decision
Choosing Mistral or a local model is not a patriotic gesture. It helps when flows, logs and access rights become easier to defend.
What the setup teaches
Local and European AI matter when they change the risk profile: sensitive data, vendor dependency, latency, auditability or repeated usage cost. They become a weak argument if the team cannot maintain the system.
Treat the model choice as architecture, not posture. The right answer may be local, cloud, hybrid or simply less complex.
What “local AI agent” really means
A local AI agent is not just a chatbot installed on an internal server.
For a startup, SMB or operational team, it can be a system that:
- receives a request or monitors a business event;
- retrieves information from authorised sources;
- prepares a reply, summary, draft or action;
- keeps a trace of what it consulted;
- asks for human validation when the risk is too high;
- routes some tasks to a local model, a European provider or a cloud service depending on constraints.
The language model is only one part of the system. Orchestration — the layer that decides what to do, with which data, under which limits — often matters more than the name of the model.
Here, “Hermes” describes an orchestration approach: several tasks, models and validation steps coordinated by explicit rules. The agent is not a single black box. It becomes a control layer that connects tools, models, human review and business rules. For a company, that changes the success criteria: data access, traces, validation, operating cost and the ability to correct mistakes.
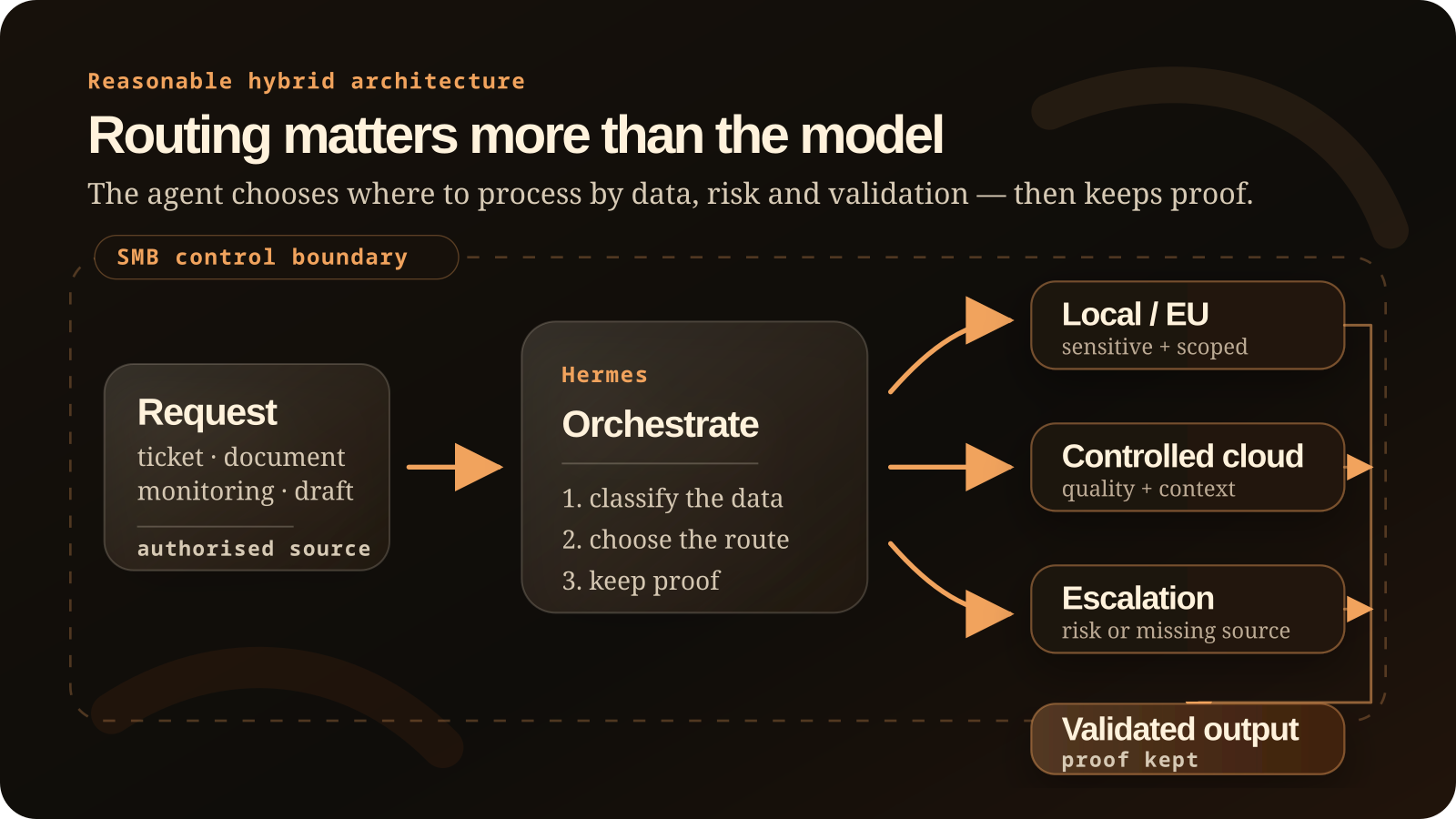
Executive summary
- Choose local or European when data is sensitive, the use case is well scoped and someone can operate the infrastructure.
- Choose controlled cloud when model quality, speed of prototyping or ease of operation matters more than local hosting.
- Choose hybrid when you want sensitive tasks under tighter control while still using cloud models for harder requests.
- Do not choose only a model: define sources, permissions, validation steps and logs first.
When a local or European LLM is genuinely useful
Local or European deployment becomes interesting when it reduces specific risks without blocking practical AI use. In this article, Mistral is a concrete example of a European player to evaluate, not a shortcut that solves everything. A company still needs to check the available models, usage terms, actual hosting, subprocessors, logs, possible data reuse and deployment options that fit the use case. Mistral AI’s public website, deployment documentation and local deployment documentation are useful starting points, but they do not replace a technical and contractual review of the project.
The most common situations are below.
Quick diagnosis: local, European, cloud or hybrid?
Answer four short questions. The result gives a first route — controlled cloud, orchestrated hybrid, or local / European — without pretending to replace a GDPR or legal audit.
The result will appear here, with the first deliverable to prepare before discussing models or vendors.
01Data read
02Output produced
03Acceptable error
04Real operations
Clarify before the project: what the agent reads, what it produces, when it must stop, and what proof it keeps.
1. The data is sensitive, but the task is focused
If the agent needs to process internal documents, customer tickets, sales notes, meeting notes or procedures, the movement of data becomes central.
A local model or European solution can help reduce exposure, provided the surrounding architecture is serious: access rights, logging, retention rules, source separation and a clear policy for what may be sent to an external model. “European” is not enough. You still need to look at the contract, processing locations, subprocessors, logs and real data commitments.
Important: local does not automatically mean GDPR-compliant. The CNIL’s resources on artificial intelligence remind organisations that AI projects must be designed around data-protection principles: purpose, legal basis, information to people, security, retention, subprocessors and individual rights. A local architecture can reduce some flows, but it does not replace legal analysis or data governance.
2. The tasks are repetitive and relatively stable
A local model can be useful for tasks such as:
- classifying incoming requests;
- summarising internal documents;
- extracting information from text;
- rewriting support replies;
- preparing internal synthesis drafts;
- detecting simple inconsistencies in a file.
These use cases do not always require the most powerful model available. They mostly require good framing: examples, instructions, output formats, authorised sources, confidence thresholds and human validation.
For many teams, this is where the effort-to-value ratio is strongest. A support team can start by classifying requests and preparing internal drafts before automating anything customer-facing. The company automates useful micro-tasks without giving the agent an end-to-end critical decision.
3. The company wants negotiating power
Depending on one cloud provider for every AI use case can become uncomfortable: variable costs, model changes, availability, data policy and contract constraints.
A local or European building block avoids making every path depend on the same provider. The company can keep some tasks under tighter control, use the cloud for more complex requests and change provider more easily if the orchestration is well designed.
The key point: avoid coding the business around one model. It is better to design an agent that can call several models under clear rules.
When cloud remains the better choice
The “everything local” story is attractive, but it can become counterproductive.
1. Quality matters more than location
Some tasks require very strong reasoning, writing quality, multimodal understanding or long-context handling. In those cases, a cloud model can be easier to test, faster to integrate or better suited to the expected user experience, especially when the team wants to compare several options before investing in local operations.
If the agent prepares a complex sales proposal, analyses a large amount of information or handles nuanced conversations, organise a test on your own use cases: same instructions, same documents, same human validation criteria. Without a reproducible protocol, it is better to discuss fit for purpose than to claim that one model is generally superior.
2. The team does not yet have operational maturity
A local model requires operations: hosting, updates, monitoring, security, latency management, backups, machine cost, regression tests and incident handling. In practical terms, this can mean a suitable GPU or server, supervision, security updates, backups and, above all, a person responsible when something breaks.
For a team without available technical capacity, “local” can move the problem rather than solve it. If no one can maintain the server, follow updates and test regressions, local deployment becomes a risk disguised as control. A well-configured cloud service, with strict data rules and human validation, may be more realistic than a poorly maintained internal server.
The right decision depends less on the slogan than on whether someone can maintain, monitor and correct the system.
3. The need is still exploratory
At the beginning of a project, you learn a lot: which users adopt the agent, which requests repeat, which sources are missing, which answers need validation, and which formats actually save time.
In that phase, cloud can accelerate prototyping. Once the workflow is stable, some components can move to local or European deployment. The hybrid approach avoids overinvesting too early in an architecture that may change after three weeks of real use.
Decision matrix: local, cloud or hybrid?
Use this simple matrix before choosing an architecture.
Sensitive internal documents, well-scoped task
Often relevant option: Local or European Why: Reduces some data flows and improves control, if operations can follow.
High quality or complex context needed
Often relevant option: Controlled cloud Why: Worth testing when expected experience or integration simplicity matters more than local hosting, with strict data rules.
Unclear project or prototype phase
Often relevant option: Cloud or light hybrid Why: Lets the team learn quickly before freezing the architecture.
Recurring volumes, stable formats
Often relevant option: Local / hybrid Why: Cost and control can become more attractive once the workflow is stable.
High-risk business decision
Often relevant option: Model is secondary: human validation is mandatory Why: The issue is organisational and legal as much as technical.
For many teams, the most robust approach is often hybrid:
- local or European for sensitive and repetitive tasks;
- cloud for difficult or occasional requests;
- central orchestration to decide which path to take;
- human validation for decisions that commit the company.

This is also the principle behind Last Word’s AI support and automation work: not selling a magic server, but designing the right level of control around data, use cases and operational constraints. If you need to frame that decision, start from services rather than a model shortlist.
Sensitive data
Start with local or European options when sources are internal, personal or contractual.
Maximum quality
Keep a controlled cloud option when reasoning or long context matters more than hosting location.
Uncertain workflow
Prototype lightly, measure real usage, then move only the stable components.
What orchestration changes in practice
Without orchestration, the company often ends up with one more chatbot. It answers a few questions well, then the limits appear: no traceability, no clear rules, no data separation, no validation and no measurement of results.
With serious orchestration, the agent can:
- limit which sources it can access based on the user’s role;
- refuse some requests instead of improvising;
- choose a local model for an internal summary and a cloud model for less sensitive writing;
- ask for validation before sending an external reply;
- keep a trace of consulted documents;
- produce a structured output instead of a long unusable answer;
- flag ambiguous cases instead of hiding uncertainty.
This control layer is often the difference between an impressive demo and a tool a team can actually use.
A simple example: an internal support agent can search a knowledge base, summarise relevant articles with a local model, prepare a reply, then ask a human to validate if the request touches a contract, personal data or a commercial commitment. The model helps, but the workflow protects the business.
That is the logic behind a properly designed AI support agent: answer faster without removing the guardrails.
Where human validation remains necessary
An AI agent is not an autonomous employee. Even with a local, European or self-hosted model, it can make mistakes, miss a constraint, misread a document or produce an answer with too much confidence.
Human validation remains necessary for:
- binding commercial decisions;
- legal, HR, financial or medical answers;
- messages sent to customers or partners;
- changes written into a business tool;
- cases where the agent did not find a reliable source;
- unusual or emotionally sensitive requests.
Good design does not try to hide this limit. It integrates it into the product: escalation, draft mode, justification, source display, approval button and history.
That is where a company gains value: not by replacing everyone, but by removing operational noise while keeping important decisions in the right place.
A practical local, cloud or hybrid choice
- Local: useful when data must not leave and the team accepts more operations work.
- Cloud: useful when quality, speed and maintenance matter more.
- Hybrid: often realistic: sensitive flows isolated, general tasks externalised.
- Human: still needed for business decisions, even with a sovereign model.
FAQ
Before choosing Mistral, another European model, a local open-weights model or a cloud API, ask these questions:
- What data will the agent read?
- What data is it forbidden to read or transmit?
- Who can trigger the agent?
- What output does it produce: draft, recommendation, action, customer message?
- When must it stop and ask for validation?
- What trace do you keep of its sources and actions?
- What level of latency is acceptable for users?
- Who maintains the infrastructure if the model is local?
- How will quality be tested after a model or prompt update?
- What happens if the model gives a bad answer: who is alerted, how is it corrected, and how do you prevent the same error from recurring?
If these questions are unanswered, model selection is happening too early.
Does a Mistral or local model guarantee GDPR compliance?
No. It can help reduce some transfers or dependencies, but compliance depends mainly on the data processed, legal basis, access rights, retention rules, logs and human validation.
When should cloud be preferred over a local LLM?
When the need is still exploratory, answer quality matters most, or the team is not ready to operate local infrastructure. A controlled cloud setup can be safer than a poorly maintained local one.
What is the right first test for an SMB?
Choose a bounded workflow with identified data, verifiable outputs and a human validating sensitive cases. The model choice should come after that scoping work.
If the data is personal or contractual
Do not start by comparing models. List sources, access rights, traces, retention rules and forbidden outputs. Only then decide what can remain local, European or cloud-based.
If the team mostly wants to learn fast
A controlled cloud prototype may be more reasonable than local infrastructure too early. The control point: no sensitive data without explicit rules, and a real usage review after a few weeks.
If the topic commits a customer or business decision
The model should not decide alone. Plan human validation, visible sources, history and an escalation path. The agent prepares; the business validates.
A reasonable architecture for an operational team
A pragmatic architecture can look like this:
- Map use cases: support, monitoring, extraction, synthesis, writing, back office.
- Classify data: public, internal, sensitive, personal, contractual.
- Define authorised routes: local, European, cloud or refusal.
- Create structured outputs: drafts, action lists, control tables, tickets.
- Add human validation wherever risk outweighs the automation gain.
- Measure real usage: time saved, corrected answers, human escalations, recurring errors, requests refused because no source was available.
- Review the architecture after a few weeks instead of pretending it is perfect from day one.
This progression avoids two classic mistakes: building a heavy local setup before validating the need, or sending sensitive data too quickly to an external service because no rules were defined.
What to keep: useful sovereignty is a design question
A local or European model can be an excellent building block for a startup, SMB or operational team. It can reduce some risks, reassure stakeholders, improve data control and unlock use cases that would be hard to justify with an unframed external API.
But it is not enough. The value comes from orchestration: what data enters, which model works, what output is produced, what trace is kept, and when a human takes over.
If you are hesitating between local, European, cloud or hybrid, the best starting point is not an abstract benchmark. It is a short workshop on your data, risks and real workflows.
Last Word can help scope the data, choose the architecture and define validation steps before building the agent. To discuss it, contact us.